
Fraudmanagement

Heute betrachte ich ein weiteres Thema aus der Sicht des Händlers: Fraud Management.
Da aber der Bereich Fraud Management ein sehr weites Feld ist, möchte ich das Thema ein wenig eingrenzen: Im Scope sind Online-Händler, die in irgendeiner Form mit Betrug konfrontiert sind. Nach einer Studie von Junpier werden die weltweiten Ausgaben zur Fraudbekämpfung im Onlinehandel mit 7,6 Milliarden USD geschätzt, und sollen bis 2022 auf 9,3 Milliarden USD steigen.
Dieser Artikel soll einen Überblick darüber geben, welche Möglichkeiten es gibt, den Online-Betrug zu vermindern und worauf Ihr dabei achten müsst.
Ein Gastbeitrag von Moritz Königsbüscher

Grundprinzipien
Für eine effektive Fraudbekämpfung gibt es eine Reihe von Grundprinzipien, die unabhängig von der Art der Fraud-Bekämpfung sind:
Mach es dem Fraudster schwerer als bei den anderen
Klingt einfach, ist es auch: Fraudster haben – üblicherweise – keine Animositäten gegenüber dem Händler, bei dem sie aktiv sind. Die einzige Absicht der Fraudster ist, ihr Fraud-Ziel zu erreichen. Dabei gehen sie den Weg des geringsten Widerstandes. Wenn Betrugserkennungs-Maßnahmen deren Aufwand höher werden lassen als er es bei einem anderen Händler ist, gehen sie dorthin.
Verstehen der (Fraud-)Intention
Um Fraud effektiv bekämpfen zu können, hilft es ungemein, die Motivation der Fraudster zu kennen – also zu verstehen warum die machen, was die machen. Sobald man diese Erkenntnis hat, lassen sich die Maßnahmen gezielt treffen.
Ein Beispiel: Bei einer Online-Plattform kam es zu hohen Chargeback-Quoten. Vermutlich wenige Fraudster kauften unzählige Subscriptions, ohne jedoch die Plattform so zu nutzen, wie es die normalen User tun. Ein normaler User hätte z.B. nicht sofort nach der Anmeldung gekauft, weil die paid-features erst nach längerer Nutzung interessant wurden. Ein normaler User änderte auch den automatisch generierten Usernamen in einen für ihn interessanten – die Fraudster taten das nicht.
Letztendlich waren die Fraudster nur daran interessiert zu prüfen, ob die ihnen vorliegenden Kartendaten verwendet werden können – und das bekamen sie heraus, wenn eine Subscription erfolgreich gekauft wurde. 80% der Versuche waren nicht erfolgreich. Ein paar Checks beim Checkout, die dann das (nicht-)Verhalten der Fraudster auf der Plattform prüften, machte das Massen-Checken der Karten so schwer, dass es nach ein paar Monaten keine Probleme mehr gab.
Ein anderes Beispiel: Bei einem Versandhändler kann es wiederum wichtig zu wissen sein, welche Produkte für den Fraudster den größten Wert bieten – sei es bezüglich des Wiederverkaufswertes oder der Chance, die Waren einfach weiterverkaufen zu können. Bestseller wie Spielekonsolen oder Fernsehgeräte sind solche Kandidaten. Diese Produkte haben dann ein höheres Fraudrisko als andere Produkte und können bei der Fraudbekämpfung besonders berücksichtigt werden.

Nutzen aller Informationen
Damit ein Fraud-Management-System, egal welcher Art, informierte Entscheidungen treffen kann, sind alle verfügbaren Informationen zu berücksichtigen. Bei dem häufig vorzufindenden Setup, bei dem der PSP die Fraudentscheidungen fällt, werden dann nur die Informationen verarbeitet, die der PSP hat. Diese reichen aber u.U. nicht aus, um das gesamte Bild zu sehen, so dass die Fraudbekämpfung nicht so effektiv ist, wie sie sein könnte.
Verhaltens-Informationen, die der Händler über den User hat (z.B. die Aktivität des Users auf der Plattform, siehe Beispiel oben) können wichtig sein und sollten bei der Fraud-Entscheidung berücksichtigt werden. Manche Fraud-Systeme erlauben dafür auch die Übergabe von zusätzlichen Informationen oder einer beim Händler berechneten Fraud-Score, die dann zu der Fraudscore beim Fraud-Dienstleister (z.B. PSP) addiert wird.
Die Kunst ist es dann, aus der Menge an verfügbaren Informationen diejenigen herauszusuchen, die relevant für die Fraudentscheidung sein können.
Ständige Iteration der Erkenntnisse
Im Grunde ist das Betreiben von Fraudmanagement ein ewiges Katz- und Mausspiel. Die Fraudster sind kreativ und lassen sich immer neue Wege einfallen, ihr Ziel zu erreichen. Die Fraudmuster verändern sich und die Händler müssen in der Lage sein, darauf in angemessener Zeit reagieren zu können.
Kombination von mehreren Indikatoren zu einer Fraudentscheidung
Ein Grundprinzip bei der Fraudbekämpfung ist, dass Fraud-Indikatoren für sich alleine immer einen Hinweis geben, aber nur in Summe aller Indikatoren eine Fraud-Entscheidung möglich ist.
Einfaches Beispiel:
Ein Kunde hat eine Deutsche Rechnungsadresse und die Lieferadresse in den Niederlanden. Das ist untypisch, aber noch kein Beleg für Fraud. Wenn der Kunde dann noch eine in UK herausgegeben Kreditkarte verwendet, wird es spannend. Wenn da noch eine Email-Domäne eines Anonymisierungsdienstes (z.B. mailinator.com) hinzu kommt, dürften die allermeisten Fraud-Systeme den Kauf ablehnen. Jeder einzelne Indikator für sich, ohne die anderen Indikatoren, reicht üblicherweise nicht um Fraud zu erkennen.
Es gibt aber auch Fälle, bei denen ein einziger Indikator ausreichend ist, um eine Fraudentscheidung zu treffen, z.B. wenn eine IBAN in einer Blacklist ist.
Mustererkennung
Fraud-Bekämpfung geschieht immer durch Erkennung von Mustern. Jeder Kauf, jede Online-Bestellung hinterlässt Spuren. Fraudbekämpfung gelingt nur deshalb, weil die Fraudster Möglichkeiten zum Betrug gefunden haben und diese wiederholt ausnutzen und dadurch ähnliche Spuren hinterlassen. Ein Fraudster, der nur einmal tätig wird, ist so deutlich schwieriger zu erkennen.
Beispiel für ein Fraud-Muster bei einem Elektronik-Retailer:
Ein User, der bisher noch keinen Kauf getätigt hat, legt sich sofort drei Spielekonsolen in den Warenkorb, ohne vorher oder nachher ein einziges Spiel für diese Konsolen anzusehen.

Ansätze zur Fraudbekämpfung
Welche Ansätze zur Fraudbekämpfung gibt es nun? Diese Übersicht ist vermutlich nicht komplett – dazu gibt es noch alle erdenklichen Kombinationen der beschriebenen Ansätze.
Excel und/oder SQL
Die einfachste Art, Fraudmuster zu erkennen kommt mit Bordmitteln aus – also ohne externen Dienstleister. Wichtig ist, die relevanten Daten zu identifizieren und zu konsolidieren – die können aus unterschiedlichen internen Quellen sowie in Form von Reports vom PSP kommen.
Excel und andere Tabellenkalkulationen bieten viele Möglichkeiten, Muster zu finden, nach Daten zu filtern und nach eigenen Kriterien die Daten zu gruppieren und zu sortieren. Mit Einsatz einer SQL-Datenbank lassen sich auch größere Datenmengen gut analysieren und aufbereiten.
Da die Analyse der Fraudmuster nach dem eigentlichen Kauf stattfindet, können die Käufe dann nicht verhindert werden – wohl aber lassen sich die Accounts der identifizierten User sperren oder der Versand noch nicht gelieferter Waren stoppen. Bestimmte Bezahlarten sind hierfür gut geeignet – z.B. Bezahlen auf Rechnung. Bei bei Kartenzahlung gibt es dazu noch die Möglichkeit, die Autorisierung von der Buchung zu entkoppeln, so dass bei Fraud die Autorisierung storniert werden kann, bevor der Betrag gebucht wird.
Kasten: Entscheidung Fraud / nicht Fraud
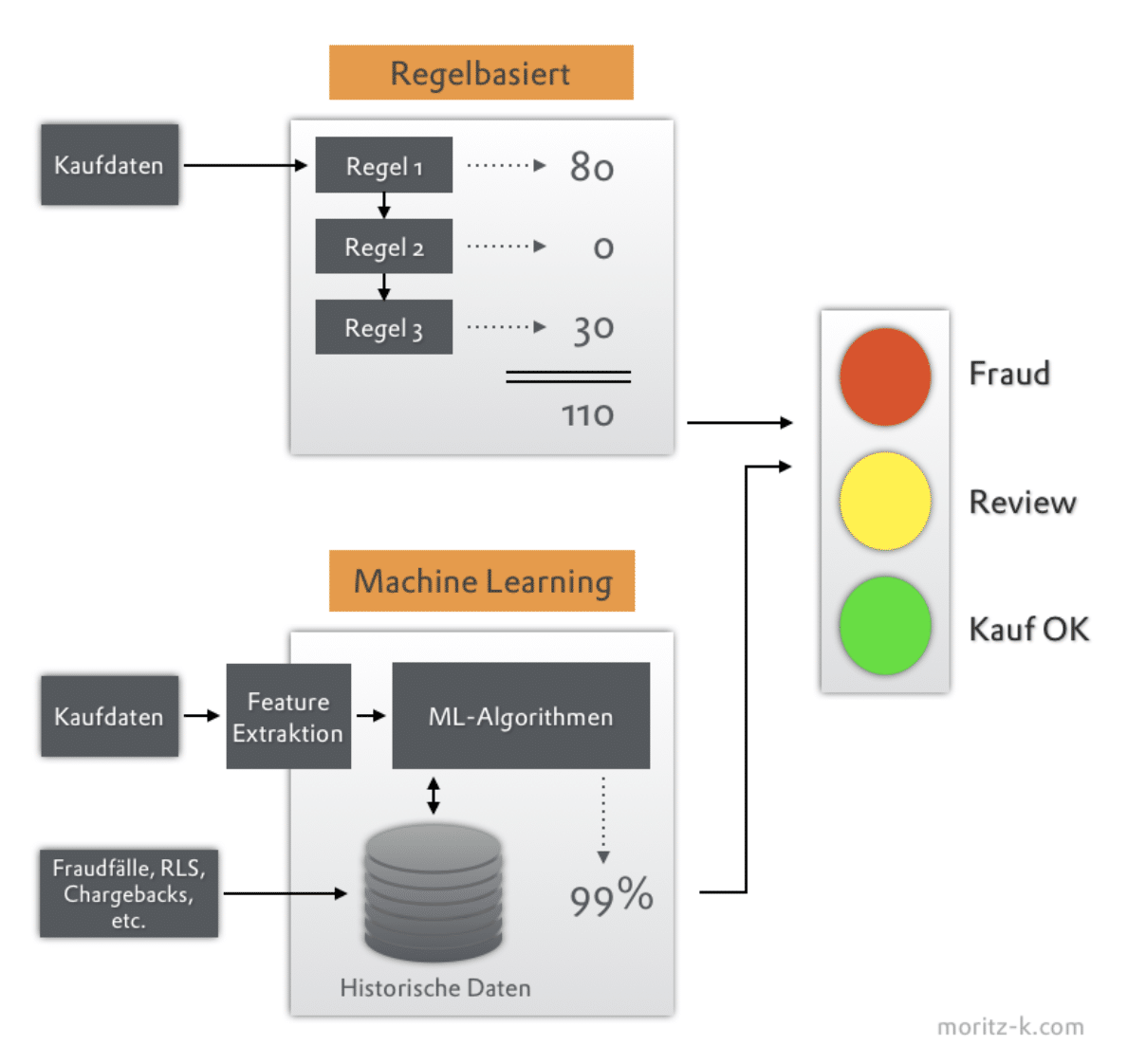
Die üblichen Methoden um Fraud festzustellen, arbeiten mit Fraud-Scores oder mit Fraud-Wahrscheinlichkeiten.
Eine Fraud-Score setzt sich aus Punkten zusammen, die aus einzelnen getriggerten Regeln zusammengerechnet wird. Jede Regel hat ihre eigene Score und geht daher gewichtet in die Gesamt-Fraudscore ein. Fraudscores sind typisch für regelbasierte Fraud-Systeme.
Machine-Learning Systeme dagegen berechnen häufig Fraud-Wahrscheinlichkeiten.
Beide Ansätze haben gemeinsam, dass ab einem vorher bestimmten Grenzwert (z.B. Fraudscore = 100 oder Fraud-Wahrscheinlickeit = 95%) Aktionen getriggert werden, z.B. automatisiertes Ablehnen des Kaufes, Einreihen der Transaktion zur manuellen Review, etc. Wenn, der Schwellwert niedrig genug ist, können die Käufe dann durchgewunken werden. Die definierten Werte sollten immer individuell festgelegt werden.
Regelbasiertes Fraudmanagement
Das klassische Fraudmanagement ist regelbasiert. Dabei werden die für die Fraud-Bewertung relevanten Daten (Transaktionsdaten, Stammdaten, historische Daten, Verhaltensdaten, etc…) auf vorher festgelegte Muster untersucht. Für jeden Fraud-Indikator gibt es eine Regel oder eine Gruppe von Regeln. Eine typische Regel ist z.B.:
“Dieser User hat innerhalb von 5 Stunden mehr als drei unterschiedliche IP-Adressen benutzt” oder “Die IBAN ist in einer Blacklist” oder “Bei dem User gab es in der Vergangenheit einen oder mehrere Chargebacks/Rückbelastungen”.
Ganz grob gibt es die folgenden Klassen von Regeln:
- Velocity (Anzahl von Ereignissen in einem definierten Zeitraum)
- z.B. “User hat innerhalb einer Stunde drei unterschiedliche Kartennummern eingegeben”
- Konsistenz (Sind die entsprechenden Daten schlüssig?)
- Z.B. Abweichung beim Land der Karte / der IP-Adresse / der Rechnungs- und Lieferadresse,, Schreibweise von Namen, Gültigkeit von email-Adressen
- Referral / Verweisung
- Diverse Blacklists/Whitelists für einzelne Datenpunkte (z.B. IP-Land oder Kartennummer)
- Proxy-IP-Adressen
- Wiedererkennung
- Device Fingerprinting, Cookies
Kasten: Device Fingerprinting
Device-Fingerprinting ist ein wichtiger Bestandteil bei der Fraudbekämpfung. Mittels Device-Fingerprinting lassen sich die Endgeräte der Nutzer recht eindeutig erkennen. Das kann mehrere Fälle abdecken:
- Sollte ein Nutzerkonto von einem Fraudster übernommen worden sein (aka Account Takeover), kann das darüber erkannt werden, dass der Fraudster dann von einem anderen Endgerät darauf zugreift.
- Käufe von unterschiedlichen Useraccounts, die aber alle vom selben Endgerät erfolgen
- Erkennen von Käufen von Usern, die bei vorherigen Käufen als Fraudster identifiziert wurden.
Sowohl die Anzahl als auch die Parametrisierbarkeit und die Komplexität, mit der die Regeln kombiniert werden können, unterscheiden sich stark von Implementierung zu Implementierung bzw. von Anbieter zu Anbieter. Eine möglichst genaue Anpassung der Regeln zum Fraud-Problem des Händlers ist dabei wichtig. Ebenso wichtig ist, die Effektivität der Regeln zu prüfen, und sie gegebenenfalls anzupassen. Eine wichtige Metrik bei der Fraudbekämpfung ist die Rate der “False Positives”, d.h. die Rate der als Fraud klassifizierten Transaktionen, die tatsächlich aber gar kein Fraud waren. Diese gilt es möglichst niedrig zu halten. Das läßt sich einfach bewerkstelligen, wenn die Fraudregeln nur schwach eingestellt werden – was dann aber dazu führen kann, dass weniger Fraud erkannt wird. Hier ist also immer eine Balance zu finden.
Der große Vorteil von regelbasierten Fraudsystemen ist, dass die leicht angepasst und verfeinert werden können. Dafür steigt mit steigender Anzahl von Regeln aber auch die Komplexität. Diese muss vone einer erfahrene Person, die alle Regeln und ihre Abhängigkeiten versteht, gemanaged werden.. Das wird dann zu einem Problem, wenn das das Verständnis zu den Regeln nicht mehr da ist, weil z.B. der Mitarbeiter das Unternehmen verlässt oder weil die Anzahl der Regeln kaum noch überblickbar ist.

Fraudmanagement via Machine-Learning
Beim Machine-Learning erstellt sich die Maschine aus historischen Daten ihre Regeln selbst – und erkennt dabei auch hochkomplexe Muster. Aber auch hier sind wieder Personen nötig – Data Engineers, die die vorhanden Daten Kunden- oder zumindest Domänenspezifisch verarbeiten.
Voraussetzung bei allen Machine-Learning-Systemen ist das Vorhandensein von genügend relevanten Daten, und zum anderen das Trainieren der Systeme mit positiven und negativen Informationen. Letztere sind z.B. von einem Fraud-Analysten als “Fraud” klassifizierte Transaktionen oder auch automatisiert erhaltene Informationen zu z.B. Chargebacks, Rücklastschriften oder nicht bezahlten Rechnungen. Das Trainieren erfolgt erst einmal auf historischen Daten, im Betrieb können dann auch neue Muster erkannt werden.
Allerdings ist es nicht immer Sinnvoll, alle Daten zu verarbeiten – hier ist Domänenwissen nötig, um die Daten zu selektieren und in ein nutzbares Format zu wandeln. Z.B. werden aus einer Lieferadresse verschiedene Parameter wie PLZ oder der tatsächliche Ort extrahiert – wenn auch eine Rechnungsadresse vorliegt, kann dann z.B. die Distanz zwischen beiden Orten berechnet werden und für die Fraud-Bewertung verwendet werden. Diese aufbereiteten Daten werden als “Features” bezeichnet.
Der Vorteil von Machine-Learning Systemen ist also, dass sehr effektiv Fraudmuster erkannt werden können, die für Personen nicht offensichtlich sind. Ebenfalls werden Machine-Learning Systeme durch Negativ- und Positivfeeback ständig trainiert – dadurch sind sie auch besser automatisierbar.. Nachteil ist, dass die dahinter liegenden Entscheidungen bei vielen Algorithmen nur recht schlecht dargestellt werden können – der Mensch muss also der Maschine vertrauen.
Device-Fingerprinting
Erwartung an Fraud-Dienstleister
Bei der Auswahl eines Fraud-Dienstleisters gibt es neben dem klassischen Kriterium Kosten eine Reihe fachliche Kriterien:
Umgang mit personenbezogen Daten / Datenschutz
Viele der bei der Fraudbekämpfung verwendeten Daten sind personenbezogene Daten oder die Kombination der Daten kann einen Personenbezug herstellen. Deshalb ist es wichtig, die Dienstleister auf Einhaltung der Datenschutzprinzipien zu prüfen und eine entsprechende Auftragsdatenverarbeitungsvereinbarung zu treffen.
Übrigens ist noch immer nicht rechtsverbindlich geklärt, wie ein entsprechender Datenaustausch mit US-Unternehmen zu bewerten ist.
Visualisierung der Fraudmuster
Das Erkennen der Fraudmuster ist ein wichtiger Teil der Fraudbekämpfung. Nur wenn die Muster auch als solche erkennbar sind, können daraus Bekämpfungsmaßnahmen entwickelt werden. Das Produkt des Fraud-Dienstleisters muss in der Lage sein, die Daten aus unterschiedlichen Datenquellen übersichtlich darzustellen, und dem Fraud-Analysten viele Werkzeuge mitzugeben, damit er die Muster erkennen kann. Das sind z.B. Filter, Gruppierungen, Aggregationen, Verläufe über Zeit etc. Ein paar Beispiele:
- Zeige mir alle Käufe der letzten 5 Tage, die einen Wert von > 100 EUR hatten und die von IP-Adressen aus Molwanien getätigt wurden
- Zeige mir alle Käufe von Usern, die vor dem Kauf mindestens drei unterschiedliche Kreditkartennummern probiert hatten
- Zeige mir die Anzahl von Käufen pro Tag im letzten Monat, und gruppiere diese nach Region, Bezahlart oder Produkttyp etc.
Visualisierung ist auch wichtig, wenn die Frauderkennung via Machine Learning erfolgt. Auch wenn Maschine diejenige ist, die den Fraud erkennt, werden die erkannten (neuen) Fraudmuster als Teil des Trainings der Maschine verwendet.
Schnelles reagieren auf sich verändernde Fraudmuster
Die Fraudmuster sind ständiger Veränderung unterlegen – sobald die Fraudster erkannt haben, dass der bisherige Weg für sie nicht mehr funktioniert, suchen sie sich neue Wege.
Sobald diese neuen Wege erkannt sind, muss es zum einen einfach sein, die neuen Muster zu erkennen, zum anderen muss es ebenso einfach sein, entsprechende Maßnahmen schnell umzusetzen. Manche Fraud-Dienstleister stellen dafür Tools zur Verfügung, mit denen ein neues Regelset mit historischen Daten getestet werden kann. Das ist Sinnvoll, um damit Fehler bei der Parametrisierung der Regeln zu finden – so können False Positives vermieden werden.
Automatisierte (in Echtzeit) und manuelle Entscheidungen
Je nach Geschäftsmodell und nach Art der Abgewickelten Zahlungen macht es mal mehr und mal weniger Sinn, Fraud-Entscheidungen zu automatisieren. So ist eine Automatisierung dann eher Sinnvoll, wenn es sich um digitale Güter bzw Dienstleistungen handelt, und erst recht dann, wenn der Service sofort nach Kauf zur Verfügung gestellt wird.
Anders sieht es z.B. aus wenn Waren versendet werden – hier sind die Beträge höher und es gibt Zeit zur manuellen Prüfung, bevor die Ware versendet wird.
Eignung für die eigene Domäne und Anpassbarkeit
Jedes Fraud-Management-Tool hat unterschiedliche Schwerpunkte und Märkte, für die es entwickelt und optimiert wurde. Wenn die Ausrichtung des Systems nicht mit dem eigenen Einsatzgebiet einhergeht, bietet das Produkt möglicherweise nur einen Teil der benötigten Funktionalität. Wichtig ist eben, dass genau die Daten verarbeitet werden können, die für die eigenen Fraudprobleme relevant sind.
Beispiel:
Fraudmanagement-Systeme von US-Anbietern verwenden viele Informationen, die bei Kartenzahlungen anfallen und kennen keine anderen Bezahlarten (ggfs. noch PayPal). Im Deutschen Retail-Markt hingegen spielen Kartenzahlungen eine verhältnismäßig kleine Rolle, wobei der Kauf auf Rechnung eine recht große Relevanz hat.
Ein Einsatz desselben System für einen Anbieter von weltweit vertriebenen digitalen Services, kann dann deutlich besser passen.
Ein gutes Fraudmanagement-System läßt sich gut an das händlerspezifische Setup anpassen, so dass der Händler keine grundlegenden Änderungen in seinem Workflow vornehmen muss.

Zum Schluß
Fraudmanagement ist ein komplexes Thema, und der Artikel hat nur die Basics berührt. Für Online-Händler wird das Thema immer wichtiger – mit effektiven Fraudmanagement kann man sich noch einen Wettbewerbsvorteil verschaffen. Nicht überraschend sind in den letzten Jahren eine Vielzahl von Fraudmanagement-Startups in den Markt eingetreten – bei der Technologie geht der Trend geht klar in Richtung Machine-Learning. Ob aber Machine-Learning die klassischen regelbasierten Systeme komplett ersetzen werden, bleibt abzuwarten. Ich tippe, dass sich eine Kombination aus Machine-Learning (Erkennen von komplexen Mustern, aber schwere Nachvollziehbarkeit durch Nicht-Maschinen) und regelbasierter Frauderkennung (Einfache Nachvollziehbarkeit und Anpassung – aber ohne komplexe Regelsets) durchsetzen wird.
Über den Autor:

Moritz Königsbüscher ist seit 17 Jahren im Bereich Payment tätig und hat u.a. als Produktmanager die Payment- und Subscription Plattform von SoundCloud gebaut.
Heute arbeitet er als freier Berater zu Payment, Fraud und Produktmanagementthemen.
Website: moritz-k.com
Autor




